John Battelle has blogged a very intriguing essay on the distinction between the dependent and the independent web. Here he makes the distinction:
The Dependent Web is dominated by companies that deliver services, content and advertising based on who that service believes you to be: What you see on these sites “depends” on their proprietary model of your identity, including what you’ve done in the past, what you’re doing right now, what “cohorts” you might fall into based on third- or first-party data and algorithms, and any number of other robust signals.
The Independent Web, for the most part, does not shift its content or services based on who you are. John Battelle: The Interdependent Web
Battelle goes on to point out:
Consider the sub-category of “content” on the web. It’s a very large part of what makes the web, the web – millions of “content sites,” ranging from the smallest blog to ESPN.com. Most of these sites don’t change what they show us depending on who they think we are. John Battelle: The Interdependent Web
Perhaps a paradigmatic example of what Battelle is getting at here would be Wikipedia, which in spite of being a construct of millions of authorial and editorial acts is pretty much the same wherever or from wherever you are looking at it. But, hold on a moment, note that Wikipedia is changing all the time, and in ways that can be hard to predict (mostly it is getting better) and it is thus highly time-dependent. Independent of the ‘self’ perhaps? Certainly, Wikipedia aims at a crowd-sourced balance and neutrality. But note the variety of languages in which Wikipedia is now developed and edited. Nevertheless, Wikipedia is a standard bearer for web independence, rapidly changing, multilingual but determinate, and in a certain sense ‘objective’. More and more our content services are becoming dependent services. They are not merely web sites. What you see and read depends on who you are and where you are, what you are doing; and you only read bits of what you are reading.
A very strong example of the way in which content services are becoming ‘dependent’ in John Battelle’s sense is offered by the iPad app Flipboard. Flipboard is a pure content service but is totally ‘dependent’, the only element of ‘editorial voice’ that emerges concerns the degree to which Flipboard selects and promotes particular channels (eg this week Davos). Flipboard is not really a web service. It is an iPad app, plain and not so simple, but it aggregates a large number of web-based publications (usually via their RSS streams) and presents them to its subscribers with Facebook and Twitter resources inter-leaved in the content mix. What you see and read in Flipboard is very dependent on the choices you have made in the past, both in Flipboard and in your daily activity on Twitter and Facebook. The user is continually creating and assembling his/her own Flipboard anthology. A hallmark of dependence: no two Flipboard users will see the same content flow — though for sure many components may be viewed in common. One of the key points about Flipboard is that it is at this point iPad-only. Flipboard is a hugely ‘dependent’ system, its shape is completely determined by its user’s profile and activity and yet it is also completely dependent on web technologies and resources though not itself a web resource. There is no Flipboard web service, of course the company has a web site, of course Flipboard uses the web very intelligently. I can link you to stuff that I am seeing and reading on Flipboard, but Flipboard is not itself a source of content. I can’t even ‘Flip’ you the page of Tweets that I am looking at right now…. (OK so here is a screen shot)
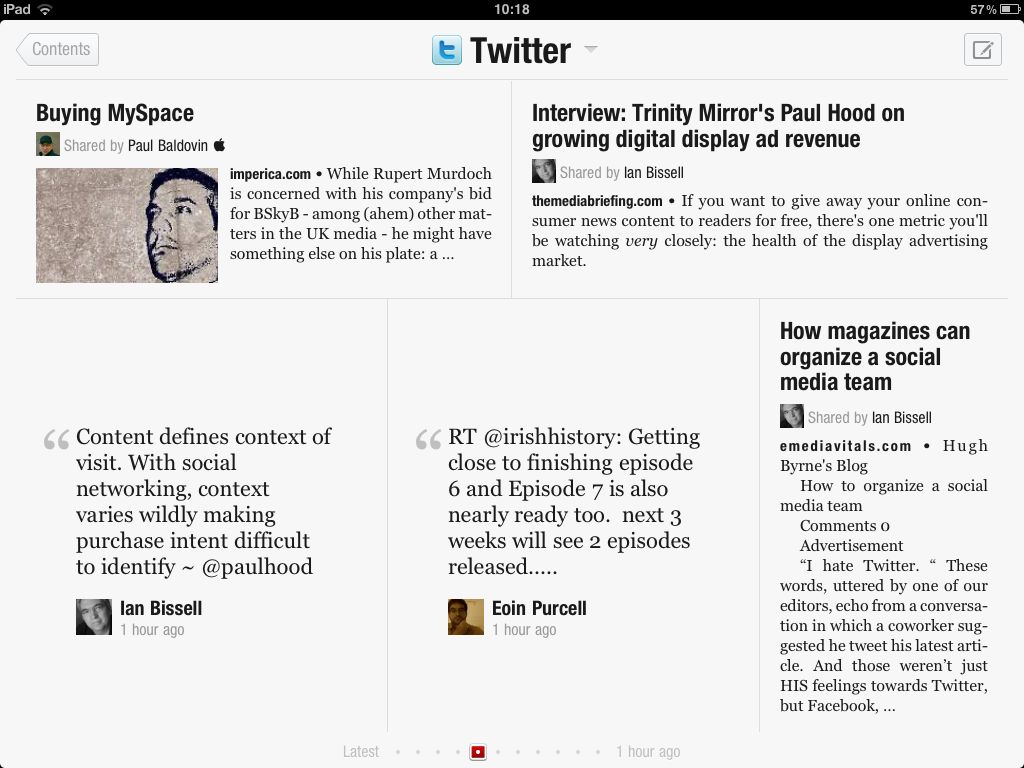
Flipboard works, and in my view it works very well, because it builds on mechanisms which were well established well before the iPad arrived. Publications, especially magazines and newspapers have been struggling to adapt to the web by developing their own ‘dependent’ web services which complement their existing and hard to monetise independent web sites. RSS feeds were an obvious example of this urge to match the daily, weekly, periodical content to the circumstances of users. But blogs and comment functions are equally significant as mechanisms through which ‘content’ resources have been trying to match their publications to the various ways in which their audience can engage with a publication through the web. What Flipboard brilliantly shows us is that the magazine (or the newspaper) itself can be pulled through to the iPad environment and appreciated or enjoyed as a quasi-magazine on the iPad. The RSS feed hauls the pictures and comments and some of the layout through into the iPad app environment.
Whether Flipboard will itself become a commercially important channel for magazine publishers is another matter. But it certainly shows the industry that it is possible to deliver magazine content to the iPad environment in a form which is both attractive and enjoyable. For magazine publishers the real challenge is now to find out how to deliver the whole magazine in various forms and via a plethora of reading devices and reading environments to readers in a consistent and self-contained way. This is why the publication “as an app” has strong appeal for publishers and the existing audience. The big challenge for the publisher is to see if the magazine or newspaper app, whether on third generation iPad or a second generation Android tablet, can be a satisfactory way of presenting a full publication better than it could ever have been in print. So that in 2015 you know that what your sister is reading on the Samsung Squiggle, or the Amazon Kindle Mk5, is the same thing as the you are reading on the iPad iNfinite…. The challenge is to make publications as dependent as they can be on the whims, devices, preferences and circumstances of the reader but as independant and as reliably referenceable as web pages and print publications. InterDependence is the goal.
Comments are closed.